
Всем давно уже известно, что высококонкурентные тематики типа: казино, займы, гемблинг, фарма и множество похожих «серых» ниш накручивается в ПС Яндекс.
Достаточно посмотреть на график из Яндекс Вордстата и будет все понятно.
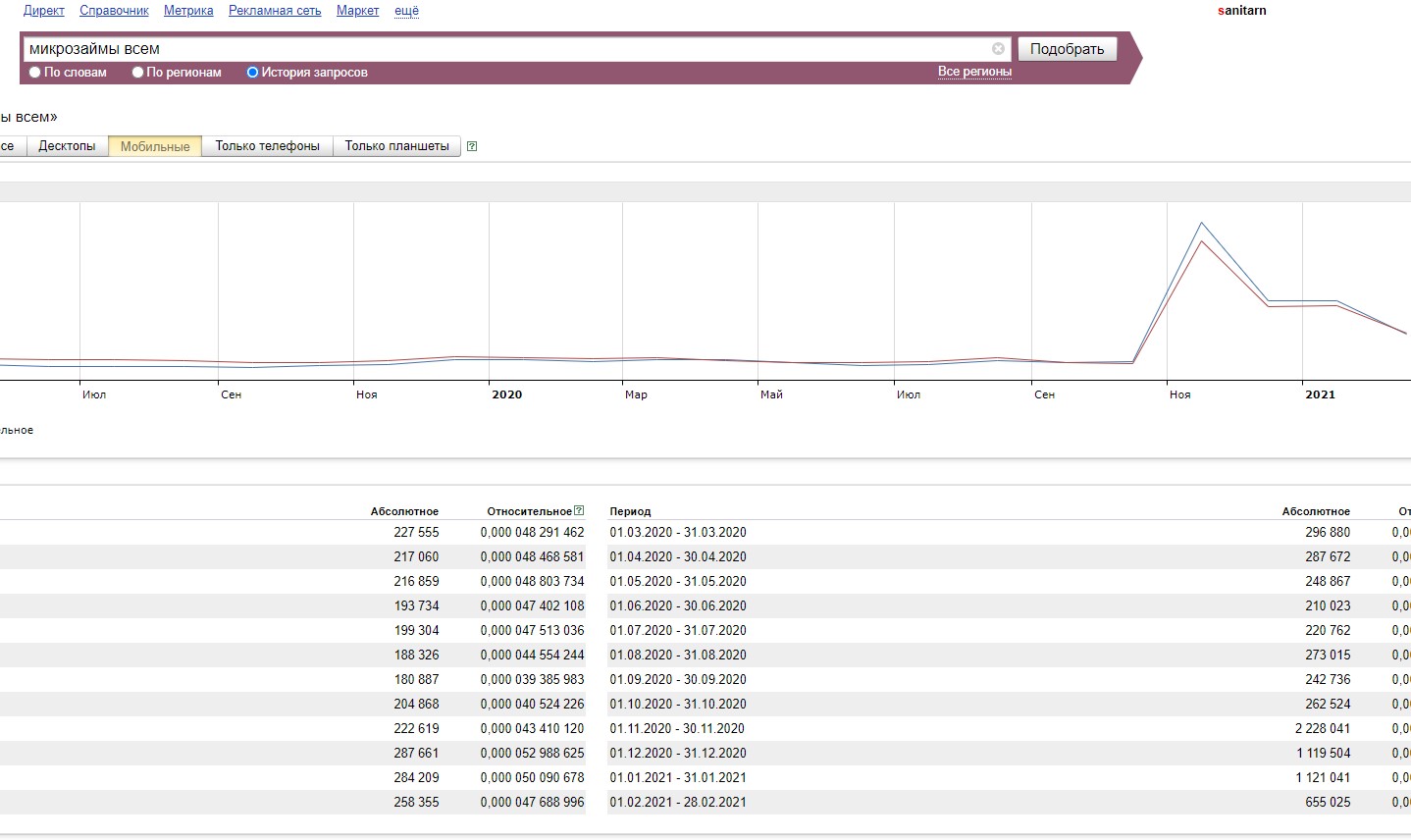
Что делать с накрутками это отдельная тема, моя задача показать как можно анализировать выдачу и сравнивать сайты в топах.
Задача состоит из 3 частей:
- Сбор серпов в пс Яндекс
- Сбор данных с сайтов, которые мы спарсили в 1 пункте.
- Анализ данных
Сбор серпов в пс Яндекс
В сборе серпов вам помогут seo сервисы или какой ни будь SEO софт из бесплатных Selka или платный Key Keycollector.
Нужно помнить, чтобы софт быстро парсил данные нужно подключить xml.
Сбор данных с сайтов
Данный пункт один из важных. Нужно определиться, что именно вы хотите проанализировать. Иногда для простых задач вполне подходит SEO лягушка, можно использовать регулярные выражение и много чего еще интересного содержит данный софт. Я бы сказал это одна из лучших программ для внутреннего анализа сайта.
Анализ данных
Подошли к основному, как только наши данные готовы к анализу, начинаем приступать. Наш анализ через 1-3 месяца может измениться кардинально, поэтому периодически нужно проводить update данных.
Посмотрим на наши данные, всего 32761 строка и 50 столбцов.
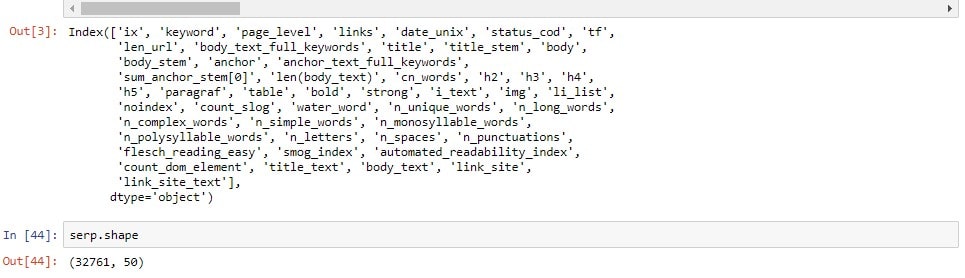
Да, конечно о 1000 факторах Яндекса речь и не идет, но как бы нам и не нужно иметь все 100X факторов. Если у вас будет стоять задача добавить коммерческие факторы, поведенческие факторы, региональные факторы, то я ниже подкину вам пару идей.
И так у нас есть 556 запросов с глубиной выдачи ТОП 30 и дважды съемом данных по Яндекс XML.
Для начала посмотрим на скриншоты по всем данным, посмотрим как наши данные распределены.
За основную метрику я возьму средние значения, вы можете взять медиану, квантили и поэкспериментировать с разницей в данных.
Данные по всем серпам
Date_unix — Возраст домена
Body_text — длина текста в символах.
Body — точное вхождение слов в Body
Body_stem — вхождение слов в Body после лемматизации
Body_text_full_keywords — Разбиваем запрос на слова.
Приводим к нормальному виду слова и производим поиск на странице %

TF всех слов в body в запросе без учета расстояний в %

Anchor — точное вхождение слов в анкорах
Anchor_text_full_keywords — вхождение всех слов в тексте.
Anchor_stem — число анкоров после лемматизации.

Title_stem = число запросов после использования лематизации в %
Title = число запросов в точном соответствие в %
Water_word = Проверяем количество слов без повторных слов в тексте, условно говоря на сколько у нас воды за счет повторных слов.
Чем выше цифра, тем более насыщенный и разнообразный текст.
Paragraf — число тегов <p> в документе
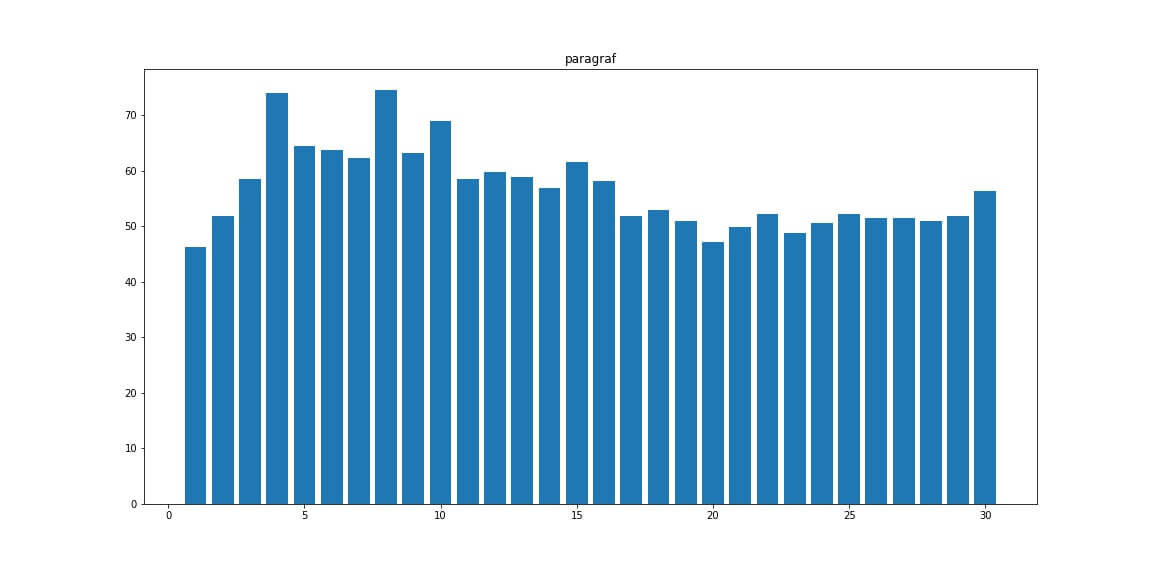
H2 — число заголовков <h2>
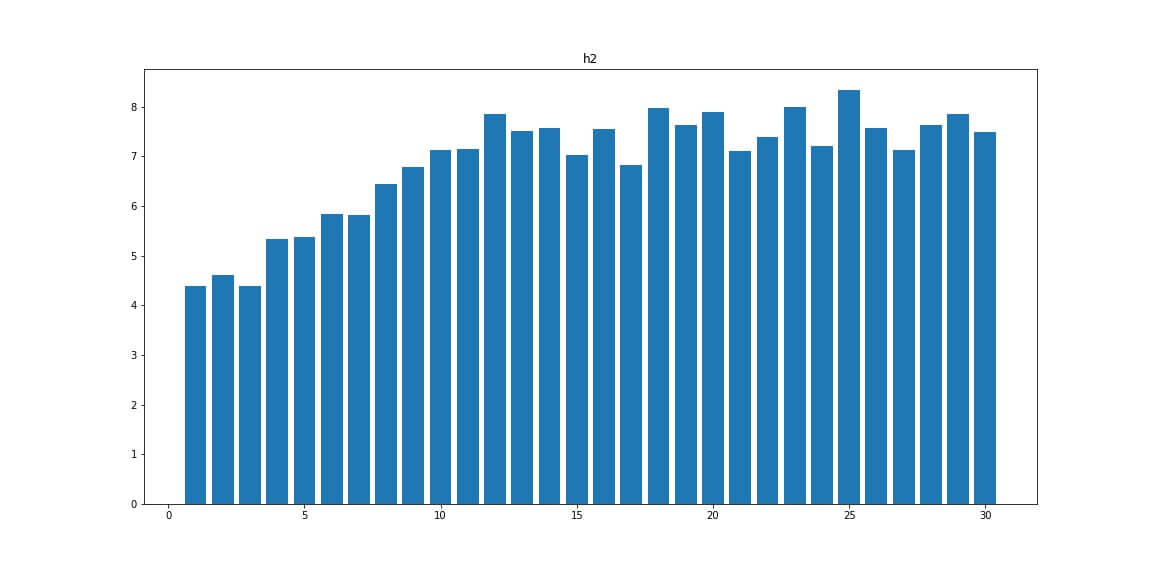
H3 — число заголовков <h3>
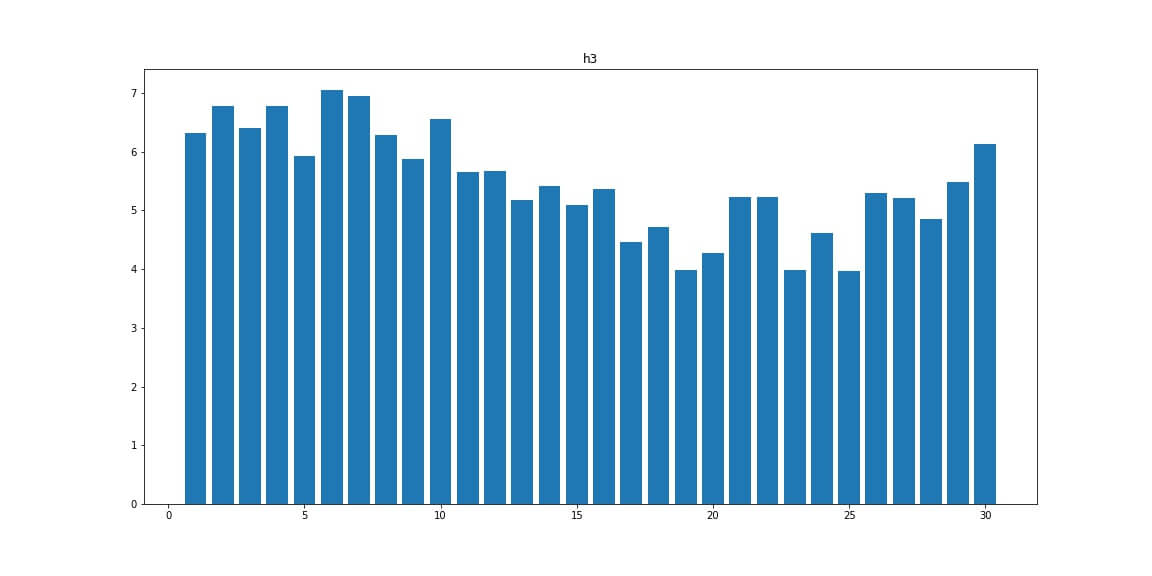
H4 — число заголовков <h4>
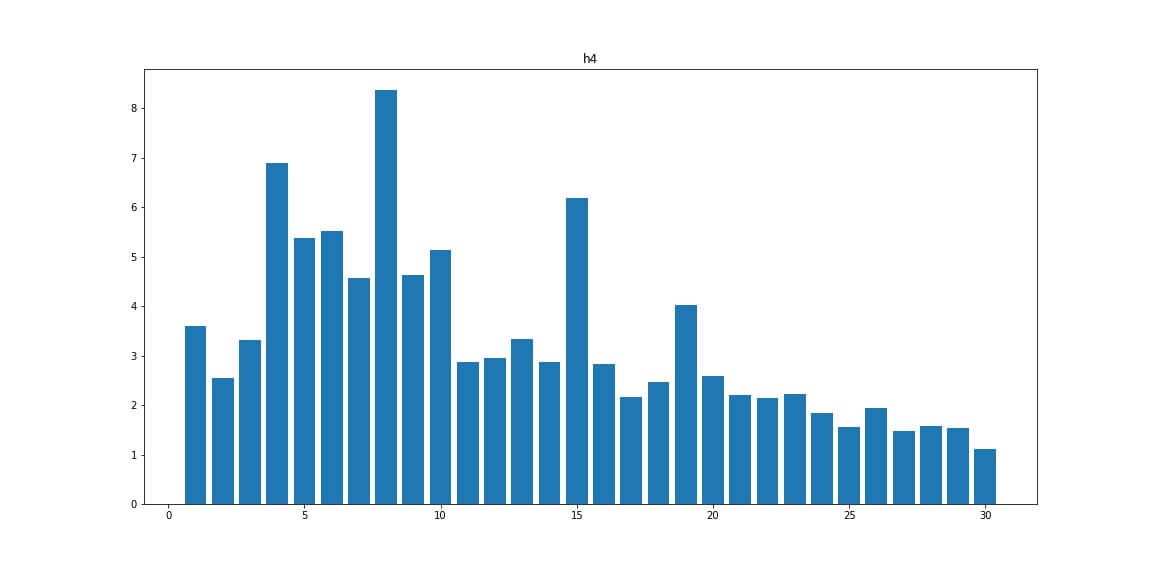
H5 — число заголовков <h5>
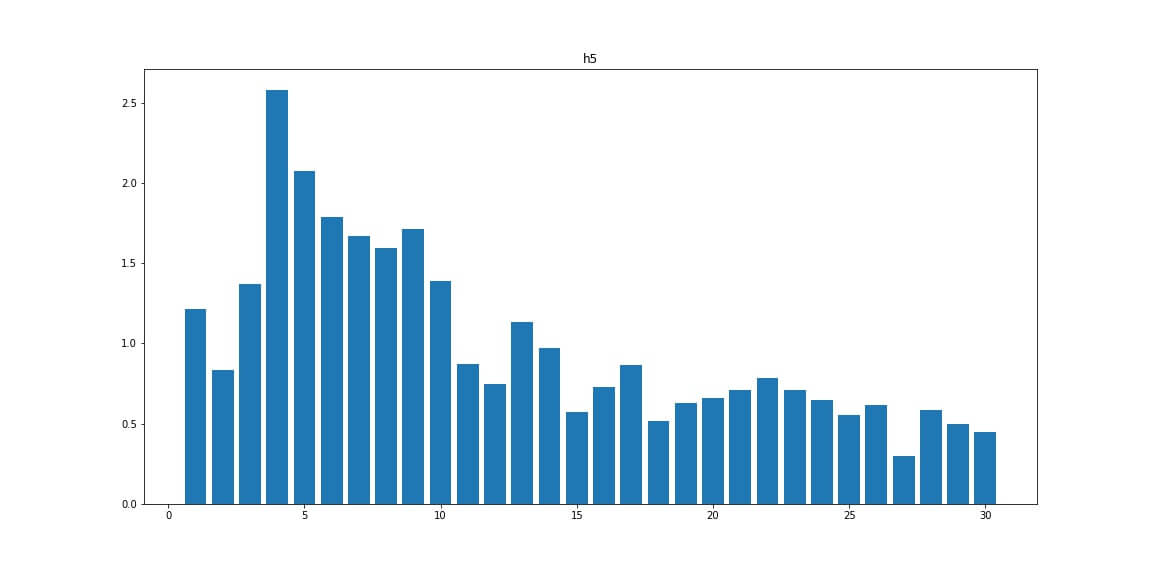
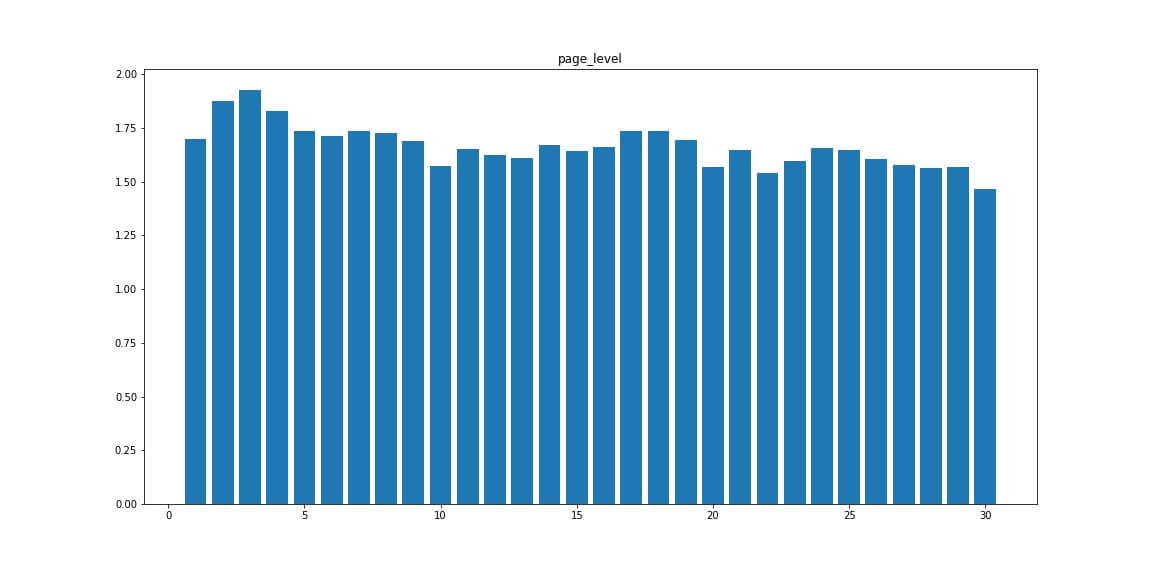
Page Level — уровень вложенности страниц
len_url — длина урла документа

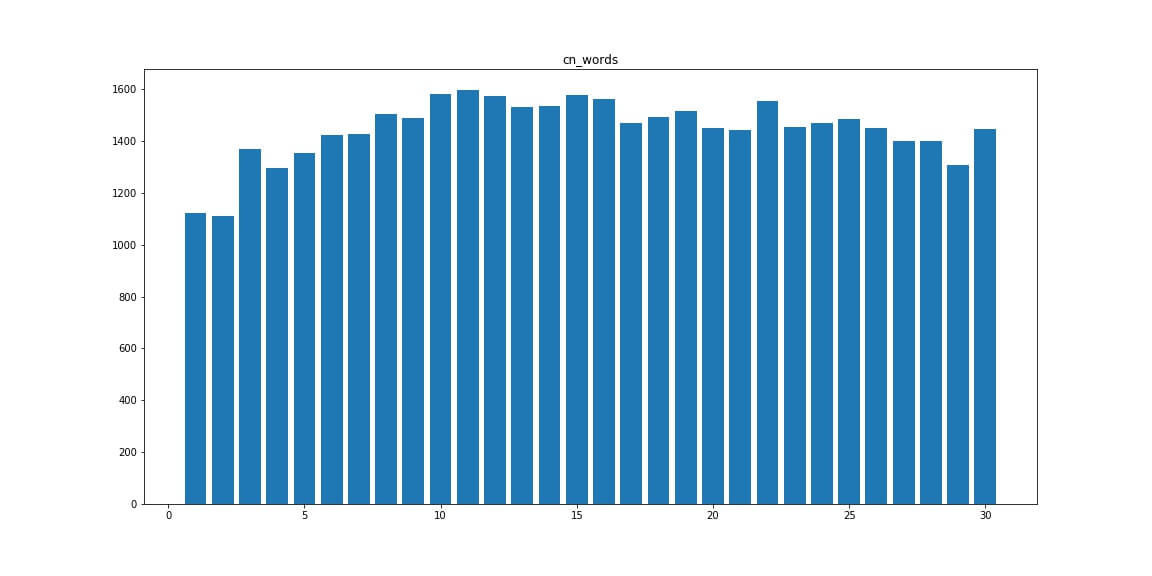
Words — число слов в документе
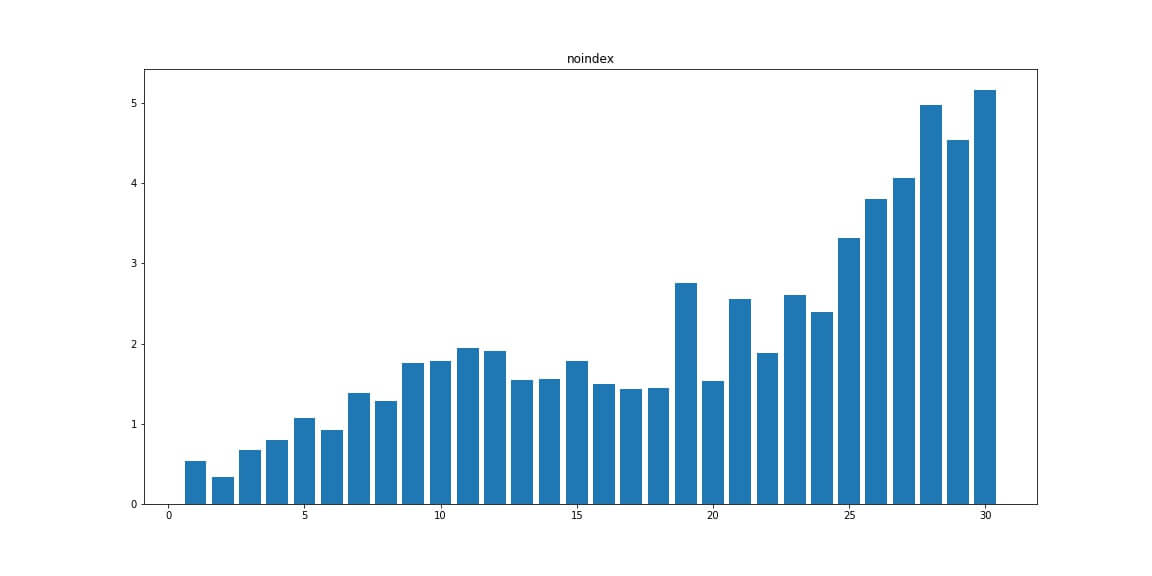
Noindex — число тегов, которые закрывают текст от индексации в пс Яндекс.
Число уникальных слов в документе
Table — наличие тега table в документах
Strong — число тегов
Li — количество списков <li> на странице
Число тегов <i>
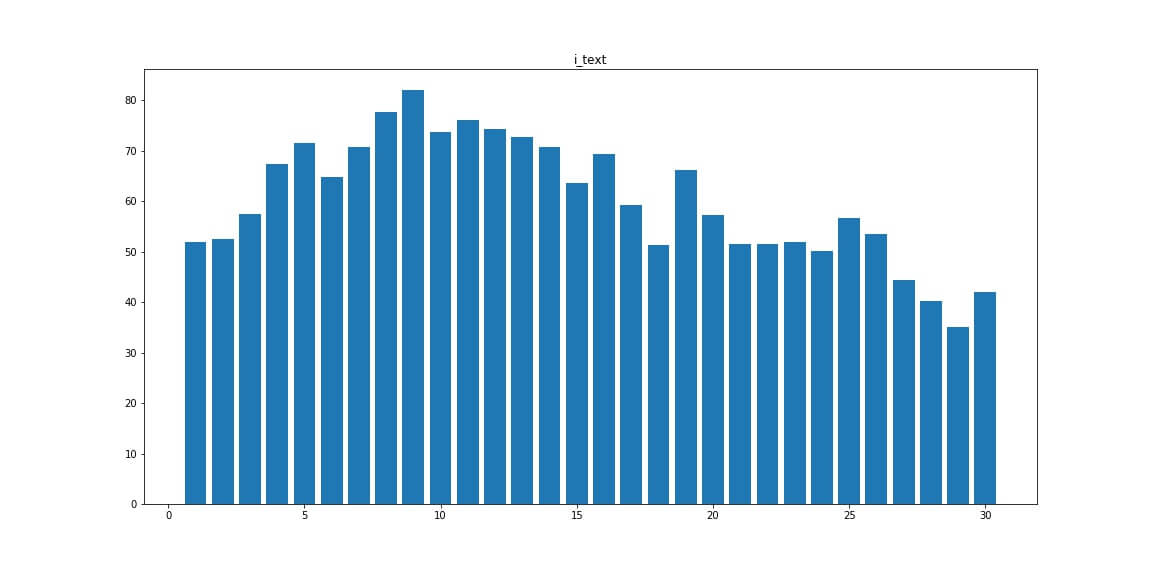
Bold — число болдов <b>

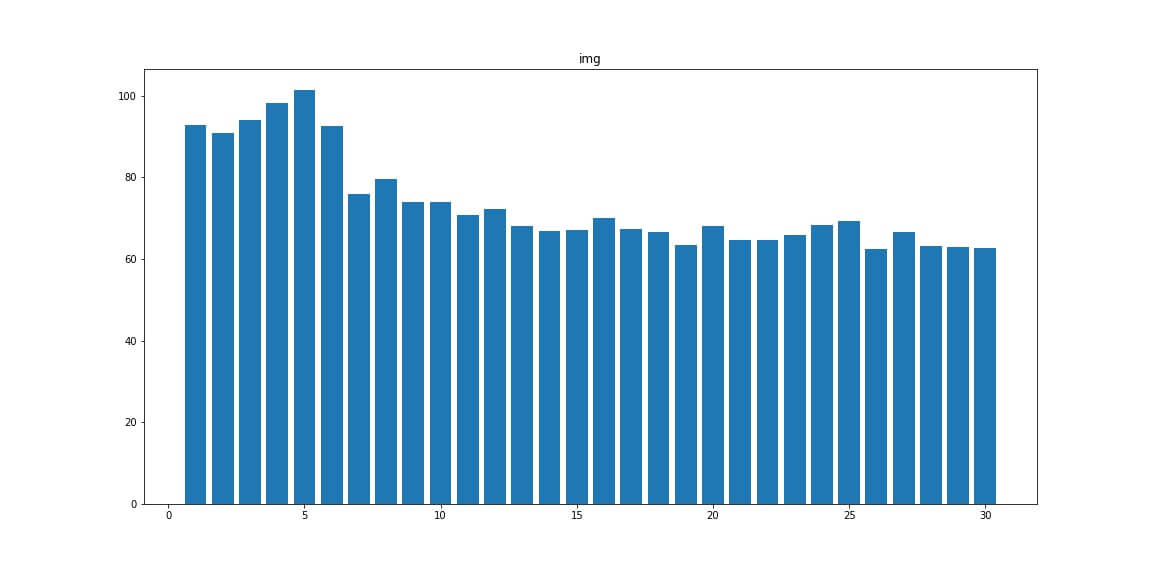
IMG — число картинок
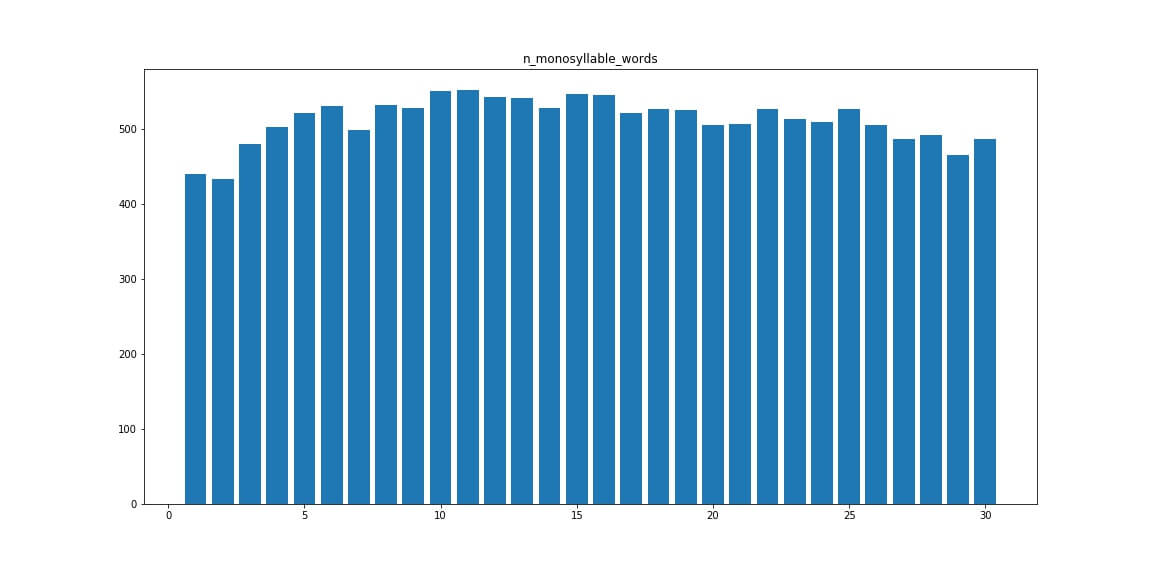
Monosyllable_words — количество односложных слов
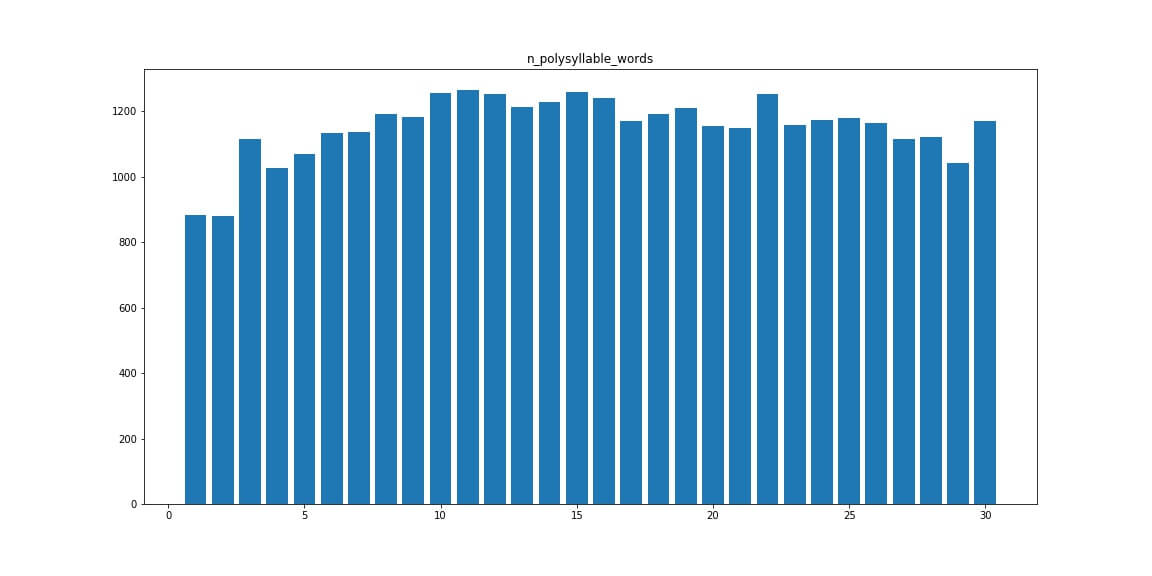
Polysyllable_words — количество многосложных слов
Punctuations — число знаков пунктуации.
Simple_words — количество простых слов
Complex_words — количество сложных слов
Spaces — количество пробелов
Long_words — количество длинных слов
Slog — количество слогов в тексте
Dom element — количество DOM элементов.
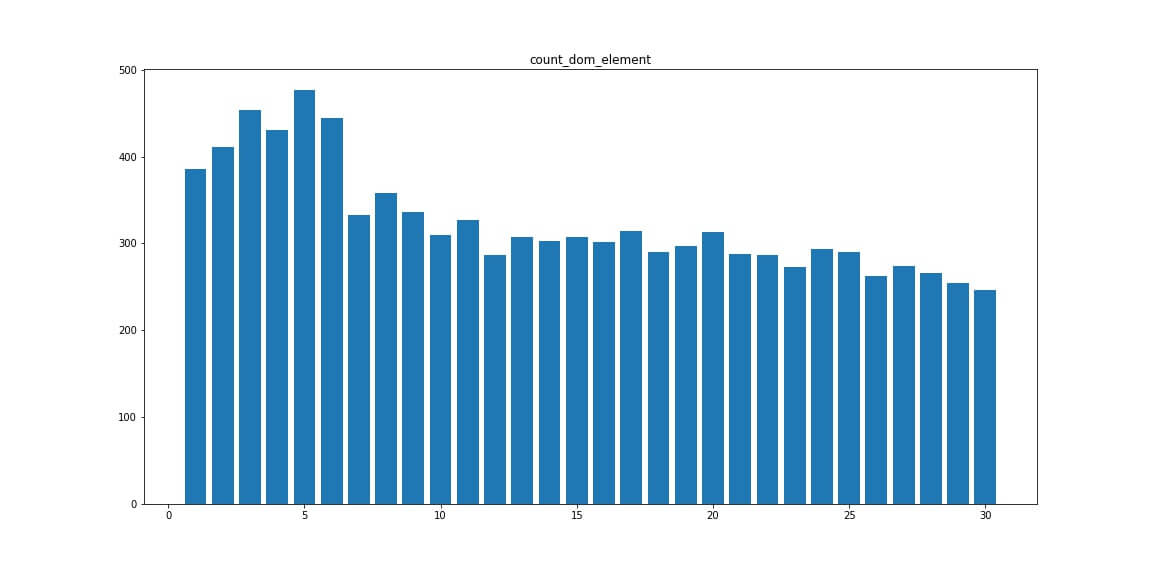
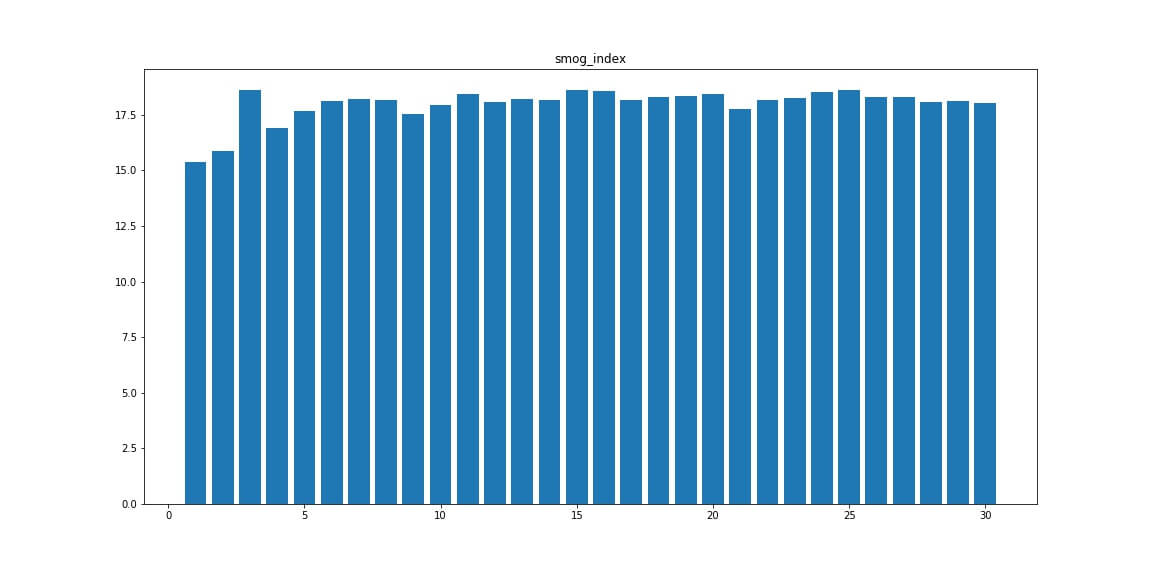
Читабельность текста Flesch reading, Smog index, Automated readability index

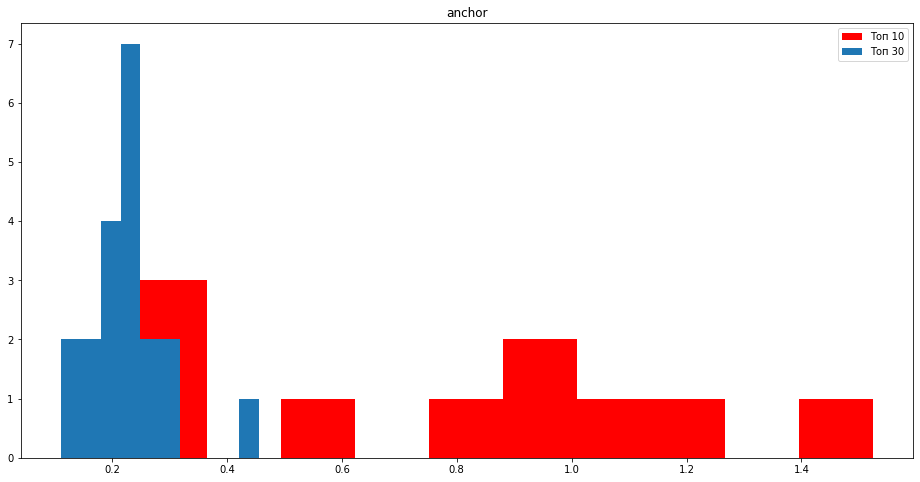
ТОП 10 vs ТОП 30
Давайте посмотрим на данные в сравнении запроса попавшего в топ 10 и не попавшего в топ поисковой системы Яндекс.
Выделю основные графики, которые меня заинтересовали.
Количество вхождений в анкорах больше у сайтов, которые находятся в топ 10.
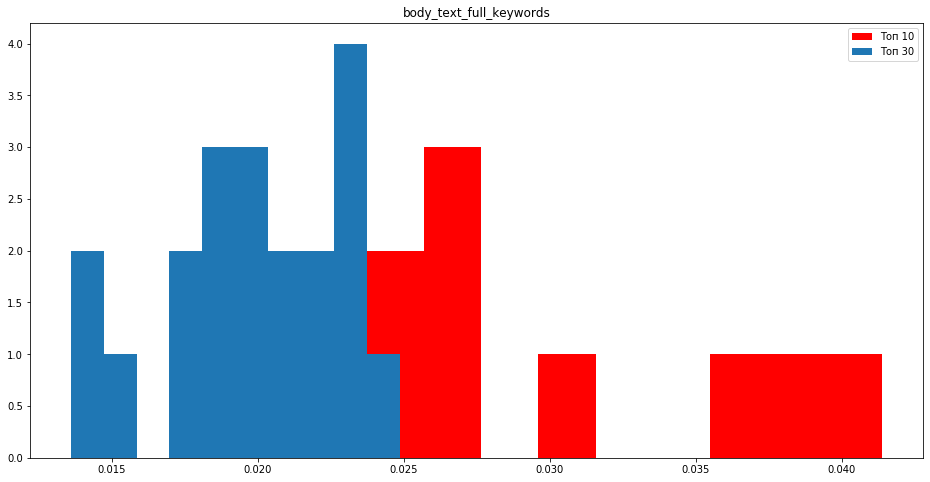
Если посмотреть на текстовые вхождения в body, также заметно, что вхождения в текст больше у сайтов в топ 10.
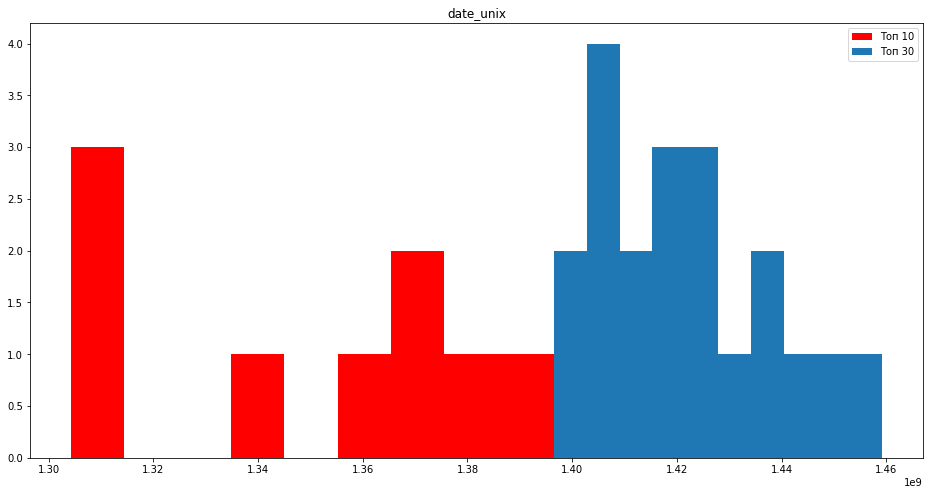
Старые сайты до сих пор играют важную роль для нахождения документов в топ 10.
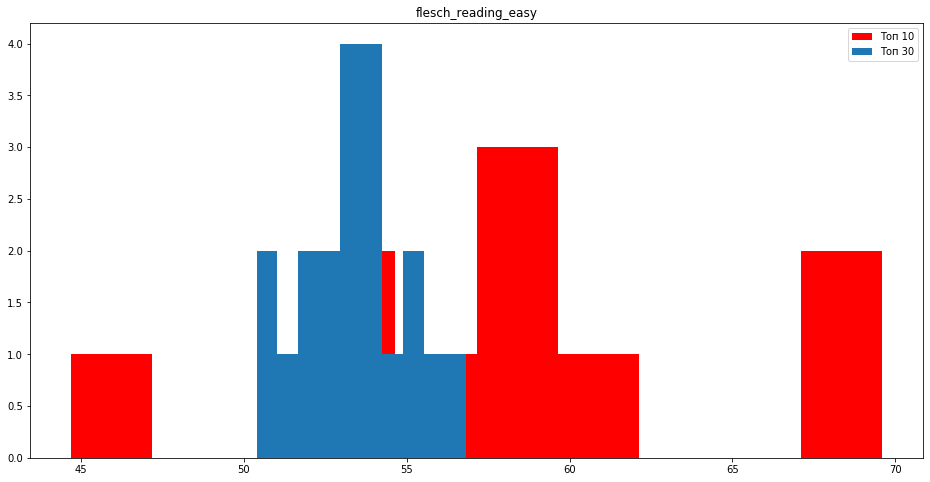
Читабельность Flesch reading выше у сайтов в топ 10.
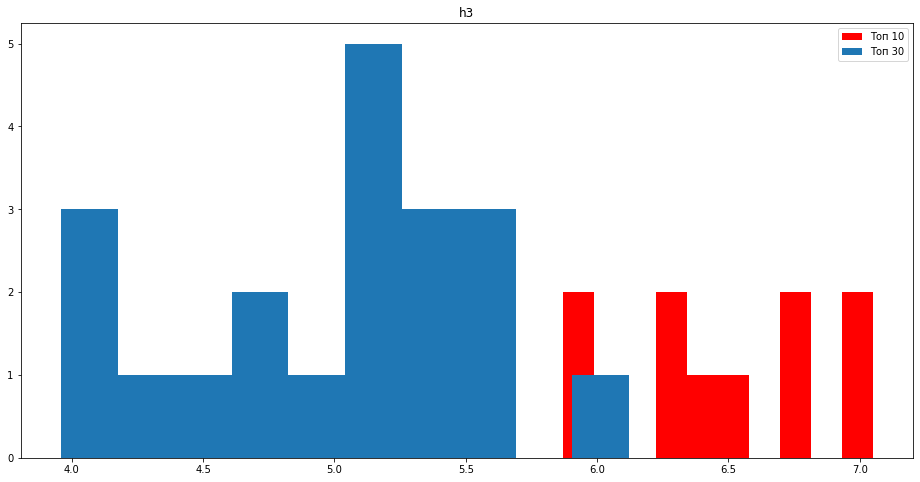
Сайты в топ 10 имеют больше заголовком h2, h3, h4, h5. Сайты из топа стараются разбивать текст на мелкие абзацы и давать ответы на самые популярные ответы в рамках документа. Нужно стараться писать текст под НЧ запросы и каждый НЧ должен быть посвящен свой абзац.
Обратим внимание на графические элементы, сайты из топа имеют в документе больше картинок, чем сайты за топ 10.

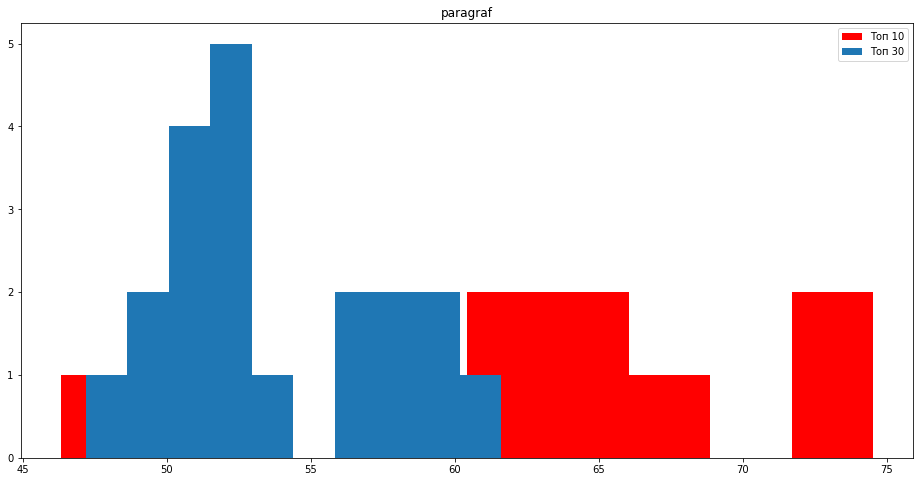
Количество тегов <p> как раз нам говорит, о том, что контент у сайтов в топ 10 разбит на более мелкие абзацы.
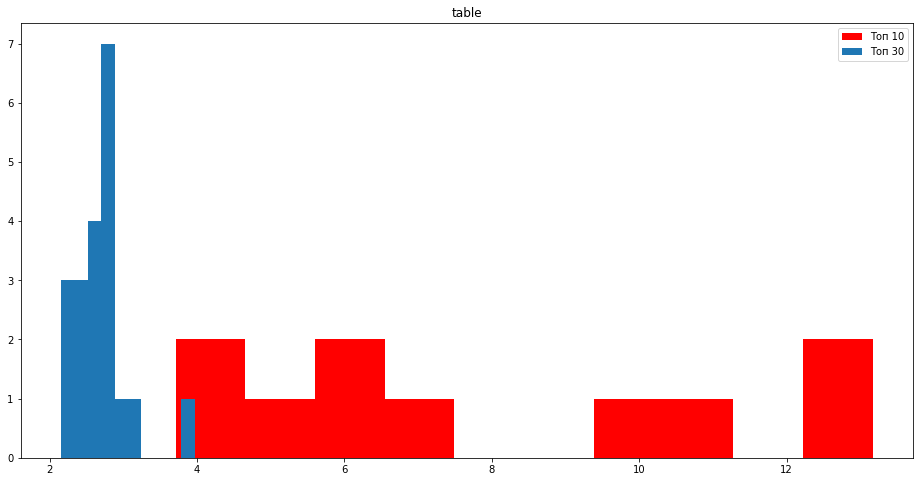
Обратим внимание на табличные данные, раскрыть более глубоко тему стараются сайты в десятке используя таблицы.
Выводы:
Капитан очевидность или майор ясен хуй?
-
- Разбивайте контент на много абзацев с релевантными заголовками под НЧ от 5-7 заголовков <h>
- Добавляйте больше графических элементов, обязательно сжимайте и уникализируйте фото.
- Списки и таблицы помогут вам разнообразить большую портянку текста.
- Отслеживайте читаемость текста например с помощью Flesch reading, хорошие показатели будут от 50 балов.
- Добавляйте вхождения в анкоры.
Обратите внимание на средние значения по топу по длине ключевого запроса:
| ТОП | Длина запроса | Количество точных фраз в документе в anchor |
| 10 | 1 | 4.25 |
| 2 | 0.62 | |
| 3 | 0.35 | |
| 4 | 0.19 | |
| 5 | 0.03 | |
| 6 | 0.01 | |
| 7 | 0.02 | |
| 30 | 1 | 26.81 |
| 2 | 1.50 | |
| 3 | 1.30 | |
| 4 | 0.59 | |
| 5 | 0.34 | |
| 6 | 0.33 | |
| 7 | 0.04 |
В следующей статье мы скоррелируем данные топ 10 VS топ 30 и построим простую модель дерева принятия решений. Я решил собрать в 10 раз больше данных, в целом это картину не поменяет сильно.





