Меня спросили, влияет ли текстовые вхождения перечисления регионов в футере или нет? На что я ответил, конечно влияет, это ведь дополнительное вхождение для поиска при региональном продвижении, а что если у вас сайт имеет нужный регион, но на сайте нет текста с данным регионом? Будет ли в данном случае текст иметь плюс для ранжирования ПС?
Имеем сайт: site.ru
- Всего запросов 1313 запросов;
- Все запросы не имеют вхождения региона в сам запрос;
- Частота запросов по Яндекс Wordstat от 100 до 10000 «WS»;
- Регионы имеют практически одинаковую товарную матрицу на сайте;
- Регионы схожи по численности населения;
- В регионе Саратов и Ярославль в футере есть текст с указанием города;
- В Тюмени, Барнауле и Рязани город не указан;
- Title, Anchor, mini-text не имеют вхождения топонима.
Анализ данных Яндекс
Наши данные:
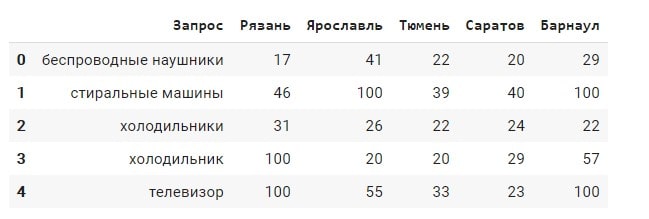
seo запросы
Посмотрим на распределение данных, средние, медианы и многие дополнительные статистические данные.
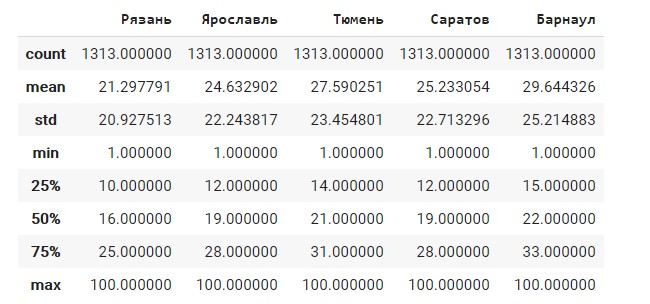
Необходимо проверить насколько у нас данные имеют нормальное распределение, заранее можно сказать, что количество запросов маленькое и позиции запросов разные, по этому выборка будет смещена.
Ярославль Яндекс
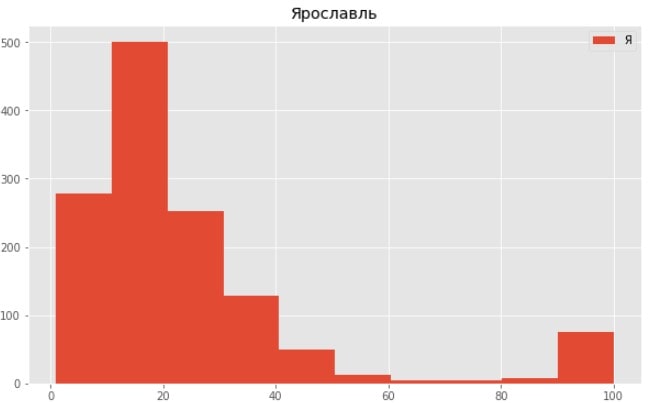
Тюмень Яндекс
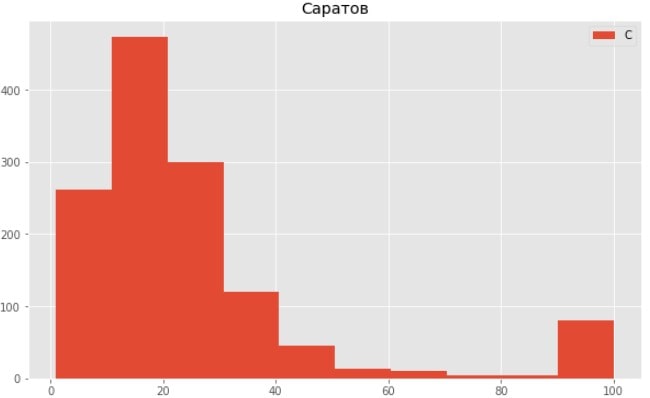
Саратов Яндекс
Барнаул Яндекс
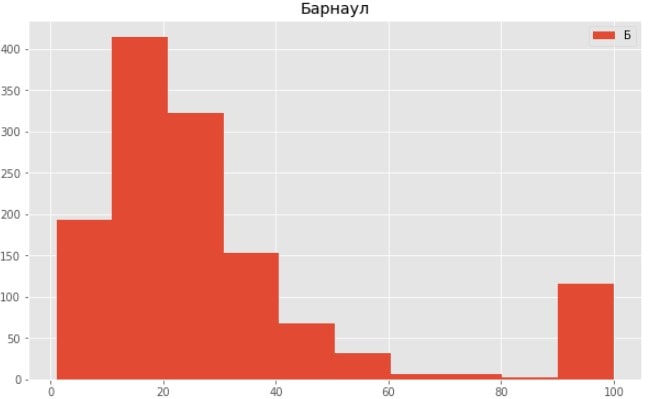
Как видим из графиков наши данные смещены в левую часть, выборка не имеет нормального распределения.
Теперь посмотрим разницу наших средних значений:
- Барнаул — не имеет в теле документа вхождения запросов с регионом,
- Ярославль — имеет вхождение запроса в тело документа.
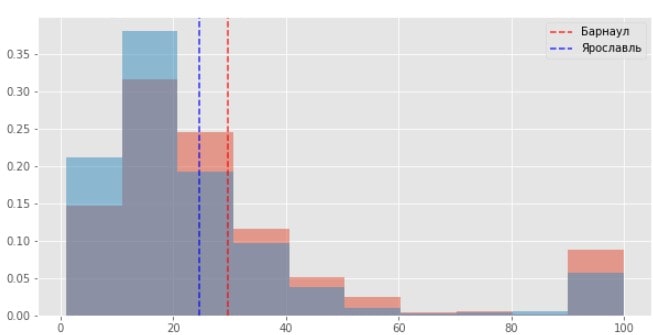
Как видим данные в целом похожи, но средние у Барнаула отличаются от Ярославля.
Так как выборка у нас не имеет нормального распределения и сама выборка данных у нас связная, будем использовать критерий Манна Уитни для нахождения статистических различий.
Для этого используем цикл for и библиотеку scipy и python.
Если значение p-value меньше <0,05, то мы отвергаем гипотезу о том, что наша тестовая выборка отличается от контрольной.
P-Value:
- Тюмень относительно Ярославль 3.802327535076659e-07;
- Барнаул относительно Ярославль 5.628706876800821e-12;
- Рязань относительно Ярославль 4.252266964660119e-09;
- Саратов относительно Ярославль 0.17013405881555488.
Можно заметить, что значение p-value у города Саратов и Ярославль больше, чем 0, 05 , а значит данные выборки не отличаются. Напомню в городе Саратов и Ярославль в теле документа присутствует текст с вхождением города.
Вывод: Наличие вхождения текста с указанием региона в тело документа влияет на ранжирование данного документа в определенном регионе.
Какой буст может дать текст с указанием региона?
Один из способов — сложить все средние значения позиций по каждому региону где нет вхождения в тело документа. И за эталон взять регион где есть вхождение в тело документа. Заметьте, вхождение должно встречаться только в тело документа!!! В других зонах типа title, анкоры, мини тексты не должны иметь вхождений с топонимом. Отнимаем наши средние выборки от эталонного среднего значение, записываем все в список. После считаем среднее значение прироста и получаем процент от числа с эталонной выборкой.
В среднем вы должны улучшить позиции на 5-7%, относительно предыдущих показателей.
Надеюсь кому то данная информация будет полезной и в следующий раз разберем Google, но там ситуация не такая радужная.






