Классификация текстов очень полезный инструмент при анализе больших объемов данных, не всегда можно глазами просмотреть десяток, сотню, а то и несколько сот тысяч сайтов для подбора сайтов, на которых вы можете разместить тематическую рекламу либо ссылку.
Для работы нам понадобится: Python с необходимыми библиотеками, База Яндекс Каталога за 2016 год с уже размеченными категориями и возьмем простой алгоритм TF/IDF.
Процесс будет состоять из нескольких этапов:
- Импортируем библиотеки
- Загружаем данные
- Производим предобработку данных
- Разделяем на тренировочную и тестовую выборку
- Используем ML для обучения
- Проверяем классификатор на своих данных
Импортируем библиотеки
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split # Разбивка на тренировочную и тестовую
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import StandardScaler, MinMaxScaler
import re
import seaborn as sns
sns.set(); # более красивый внешний вид графиков по умолчанию
from matplotlib import pyplot as plt
%matplotlib inline
plt.rcParams['figure.figsize'] = 16,8
from sklearn.metrics import classification_report, accuracy_score, f1_score, roc_auc_score, roc_curve, mean_squared_error, precision_score ,recall_score, mean_absolute_error, confusion_matrix
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
import pymorphy2
from sklearn import preprocessing
from stop_words import get_stop_words
stop_words_ru = get_stop_words('russian')
stop_words_en = get_stop_words('english')
stop_word_en_ru = stop_words_ru + stop_words_en # база английских и русских стоп слов
После того как мы импортируем все нужные и не совсем библиотеки, нам необходимо загрузить датасет.
Таблица с размеченными данными
%%time
df = pd.read_excel('Яндекс.Каталог.xlsx')
df.head(3)
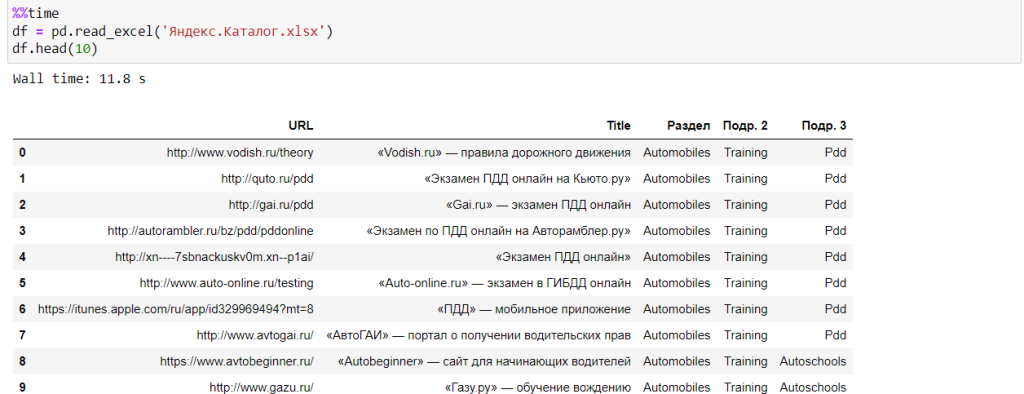
В нашем датасете мы имеем таблицу с урлами, title и 3 раздела, которые включают основной раздел и дополнительные подразделы. Мы с вами упростим задачу и будем классифицировать только раздел, при большом желании вы сможете объединить таблицу подразделов и сделать классификатор более умным.
Производим предобработку данных
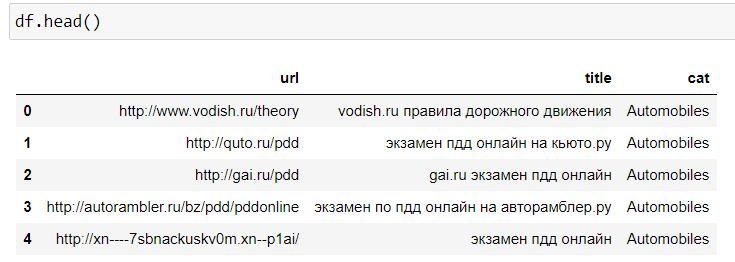
Оставим только 3 колонки урл, title и раздел, удалим дубли, если они есть, также произведем переименование колонок, приведем все тексты в нижний регистр и далее лемматизируем все тексты.
#Оставляем нужные колонки, переименовываем названия
df = df[['URL','Title','Раздел']]
df = df.rename(columns={'URL': 'url', 'Title': 'title','Раздел':'cat'})
# Переводим все в нижний регистр и удаляем спецсимволы в title
df['title'] = df['title'].str.lower()
df['title'] = df['title'].str.replace(r'^\s+|\s+|\ꞌ|\'|\«|\»|\—', ' ', regex=True)
df['title'] = df['title'].str.replace(r'\s+ ', ' ', regex=True)
#удаляем дубли
df = df.drop_duplicates(subset=['url'], keep='last')
Проверяем как выглядят наши данные.
Теперь сгруппируем наши данные и посмотрим сколько у нас всего категорий.
df['cat'].value_counts()
Всего у нас 11 категорий и больше всего сайтов в категории Бизнес, порталов меньше в 60 раз. Несмотря на то, что количество данных в разных категориях разнится, мы без проблем сможем построить наш классификатор.

Осталось текстовые категории преобразовать в численные, так как машинное обучение работает только с данными, которые преобразовывают в числа.
# Создаем целевую переменную le = preprocessing.LabelEncoder() le.fit(df['cat']) cat = le.transform(df['cat']).tolist() df['target'] = cat labels = df[['cat','target']] labels = dict(zip(labels.target,labels.cat)) # эта переменная нам понадобится чуть позже при анализе прогноза count_target = df['target'].shape count_target_unique = len(df['target'].unique())
- Число строк 105302
- Число уникальных категорий 11
Лемматизация
Применим лемматизацию, приведем все слова в первоначальную форму, количество данных уменьшится, но в данном случае нам это не помешает.
Будем использовать библиотеку PyMorphy .
corpus = df['title'].tolist() cluster = df['target'].tolist() stem_text = pymorphy2.MorphAnalyzer() lemma = [ ' '.join ([stem_text.parse(word) [0].normal_form for word in x.split()]) for x in corpus]
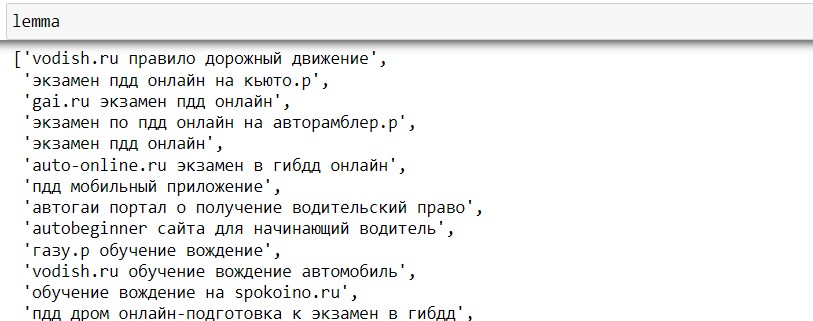
После преобразования, можно наблюдать, что слова отображаются в начальной форме слова, но есть где-то спецсимволы в виде точек, тире либо стоп-слов. Это мы сможем поправить в самом начале кода, при последующем улучшение предобработки данных.
TF/IDF Векторизация
Ограничим данные до 5000 колонок, возьмем только униграммы и удалим стоп слова.
vectorizer = TfidfVectorizer(min_df=2,token_pattern='[а-яА-ЯёЁa-zA-Z]+', ngram_range = (1,1),stop_words=stop_word_en_ru, max_features = 5000) vector_text = vectorizer.fit (lemma) vector_text = vectorizer.transform (lemma) df_data = pd.DataFrame (vector_text.toarray(), columns = vectorizer.get_feature_names())
Посмотрим как выглядит наша матрица с данными.
Табличка получилась сильно разреженной на 105302 строки и 5000 колонок , что в целом является не такой большой для современных компьютеров, такие данные легко обработать на ноутбуке с оперативкой в 12-16 гб.
Разбиваем данные для обучения
# Разбиваем данные на обучающую и тренировочную выборку data_train, valid_train, data_test, valid_test = train_test_split (df_data, cluster, test_size = 0.20)
Одна строка, которая разбивает нам таблицу для данных на которых мы будем обучаться и данных на которых мы будем валидировать нашу модель, насколько она хорошо обучилась.
ML обучение с помощью RandomForestClassifier
Используем алгоритм случайного леса, в качестве метрики качества возьмем accuracy_score, также желательно после оценить с помощью метрик F1 и посмотреть на матрицу ошибок.
model_RD = RandomForestClassifier () # RandomForestClassifier
model_RD.fit(data_train, data_test)
valid_rdf = model_RD.predict(valid_train) # Валидируем данные на данных, которые мы не видели
print(f'RandomForest {accuracy_score(valid_rdf, valid_test)}') # Сравниваем и оцениваем фактические данные и предсказанные
RandomForest 0.8388965386258962
Наша моделька без каких то гипер-параметров и тюнингов умеет предсказывать категорию сайта с точностью до 83%, что в целом очень хороший результат. Немного нужно затюнить модель и можно смело до 98% улучшить модель.
Проверяем классификатор на своих данных
Осталось сохранить нашу обучающую модель и после проверить, как она может предсказывать по тексту, к какой категории относится наш сайт или страница сайта.
import pickle # Импортируем библиотеку для сериализации наших данных
#Сохраняем наши данные
pickle.dump(vector_text_fit, open("tfidf.pickle", "wb"))
pickle.dump(model_RD, open("model_rd_forest.pickle", "wb"))
# Загружаем нашу модель, чтобы снова не обучать ее на старых данных
load_fit_tfidf = pickle.load(open("tfidf.pickle", "rb"))
load_rd_forest_fit = pickle.load(open("model_rd_forest.pickle", "rb"))
После того, как мы загрузили наши данные, нам необходимо собрать функцию, которая будет преобразовывать наши входящие тексты в необходимый для нас формат. Мы не будем писать новый код, нам просто нужно его скопировать с начала данного материала лишь изменив переменные.
def classification_preproccessing_text (text: str):
"""Передаем строку с нашими данными и на выходе получаем строку с преобразованными данными"""
text = text.str.lower()
text = text.str.replace(r'^\s+|\s+|\ꞌ|\'|\«|\»|\—|\-|\.', ' ', regex=True)
text = text.str.replace(r'\s+ ', ' ', regex=True)
return text
Теперь нам остается написать текстовые заголовки и проверить все в цикле.
Добавлю на всякий случай код, возможно вы будете это использовать.
#Проверим в Цикле наши категории
titles = ['Ресторан на выходных с детьми','Купить ноутбук в Москве',
'Здоровье и красота - женский журнал',
'Как починить автомобиль своими руками']
for i in titles:
transform_tfidf = load_fit_tfidf.transform([i])
predict_cat = load_rd_forest_fit.predict(transform_tfidf)
predict_cat = int(predict_cat[0]) # Преобразовываем тип данных с Numpy в Int
if labels.get(predict_cat): # Так как мы сразу не преобразовали численные данные в категории, производим поиск в ранее сохраненном массиве labels
print(i, labels[predict_cat])
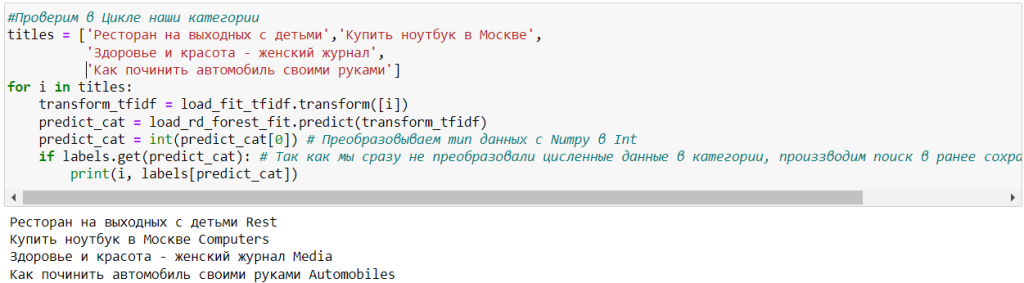
Видно, что с поставленной задачей классификатор справляется неплохо, но не идеально.
Как мы можем улучшить нашу модель?
- Использовать модели градиентного бустинга — XGBoost, CatBoost, LightGBM,
- Использовать гиперпараметры — они хорошо улучшают модель,
- Произвести чистку базы, убрать выбросы, добавить англоязычную версию title, увеличить число фичей в данных,
- Попробовать использовать нейронные сети,
- Добавить в базу новых данных.
Если нужен платный Google Colab, а денег нет, тогда воспользуйся фрибетами и испытай удачу!







